Searching SENS Through Corpus Linguistics Tools: A Basic Guide
by Fabio Ciambella, University of Tuscia, Viterbo.
The SENS project, being a digital archive, represents an interesting testbed for the analysis of corpora and the implementation of corpus linguistics tools. Albeit acknowledging the high number of tools available, this short guide aims at introducing basic examples of lexical and collocational analysis through the Voyant tools[1] and the #Lancsbox software[2], in order to show the potentials offered by both online tools and software. The examples given in the following paragraphs concern the analysis of the semidiplomatic text of Arthur Brooke’s Romeus and Iuliet, taken as a sample corpus.
Voyant tools
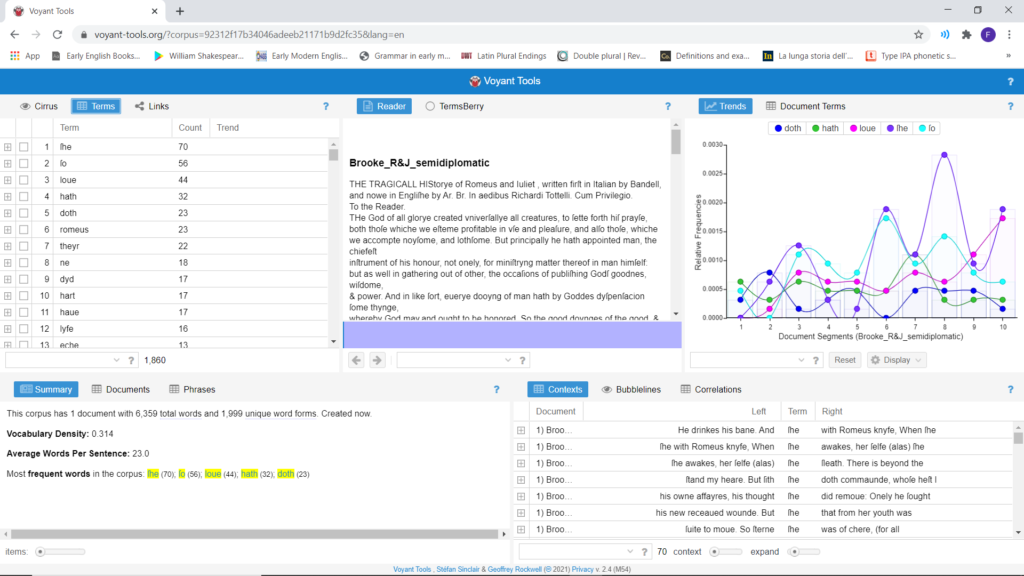
Corpora can be uploaded directly on the Voyant homepage by URL or as text files. Voyant automatically tags the text and presents the corpus analysis on a screen divided into five boxes (Fig.1) containing (1) Keywords, (2) text, (3) Keywords distribution, (4) General word count information, (5) Context for any selected node.
Fig. 1. Voyant tools’ main functions.
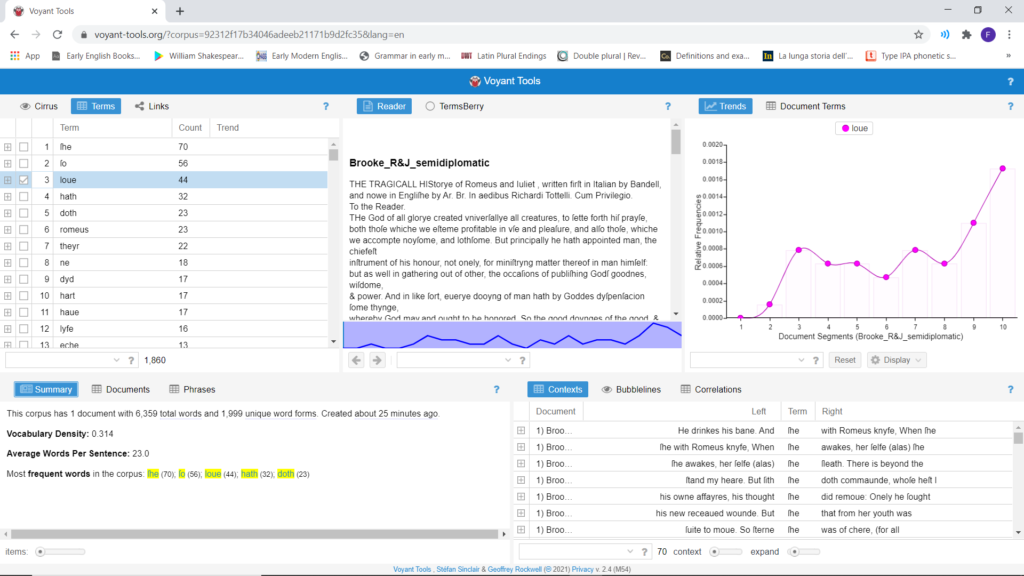
1. The Keywords tool lists the most recurring lexical words in the corpus uploaded; function words are automatically tagged and not included here. By clicking on any of these keywords, boxes (2), (3) and (5) highlight respectively portions of the text where a keyword occurs, its distribution in the corpus and main n-grams it occurs within, and its collocations (Fig. 2).
Fig. 2. Results obtained by selecting the keyword “loue”.
2. The plain text is shown in the second box with no irregular spaces, nor words in italics or bold. Only the difference between capital and small letters is maintained.
3. The Distribution tool illustrates the trend of selected keywords or a single keyword.
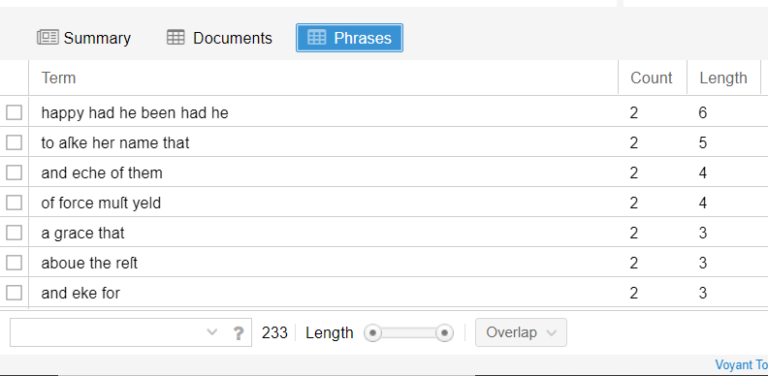
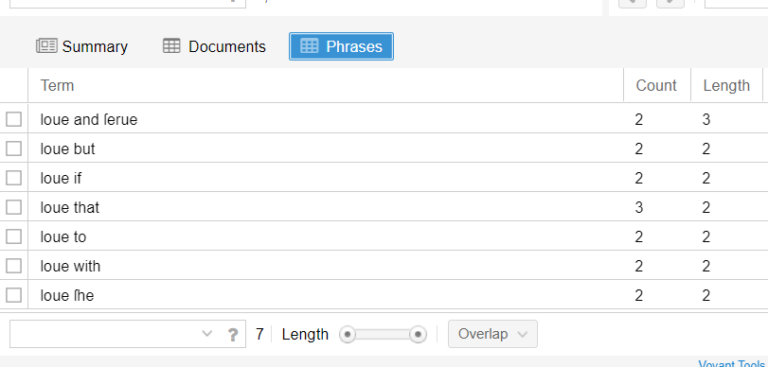
4. General information about word count is reported in the Summary tool, in terms of number of tokens, types, lemmas, TTR, most frequent words, etc. Also, the most recurring n-grams are reported by clicking on the Phrases button (Fig. 3).
Fig. 3. N-grams in the whole corpus (left) and only for the keyword “loue” (right)
5. The Context tool allows any keyword to be inserted in its collocation patterning through the Contexts, Bubblelines and Correlations functions.
#Lancsbox
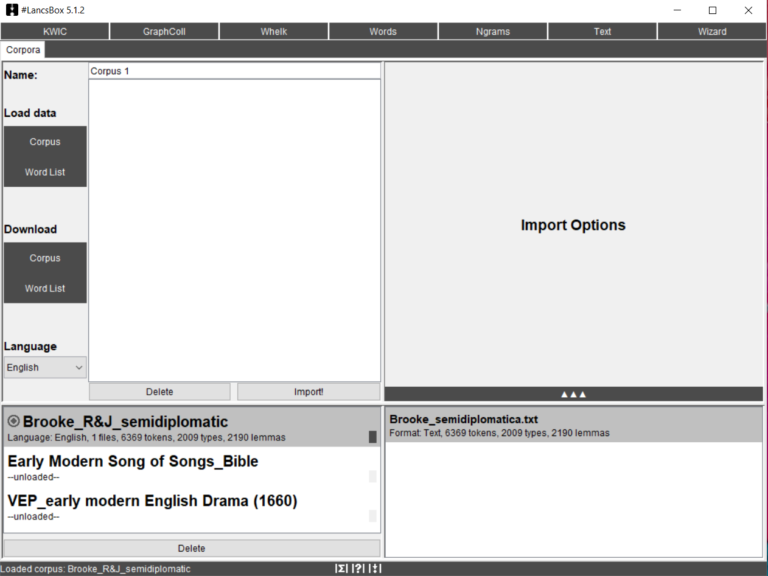
Data can be either loaded from local text files saved in different formats (.txt, .xml, .doc, .docx, .pdf, .odt, .xls, .xlsx, etc.) or downloaded from a database of corpora internal to the software itself (BNC, Brown, LOB, and others). Languages other than English can be selected, which gives users the possibility to make the software tag parts of speech (or PoS) automatically. The screenshot below (Fig. 4) shows #Lancsbox corpora tab with the same example of text file used above. Numbers of tokens, types and lemmas have been already calculated by the software.
Fig. 4. #Lancsbox corpora tab.
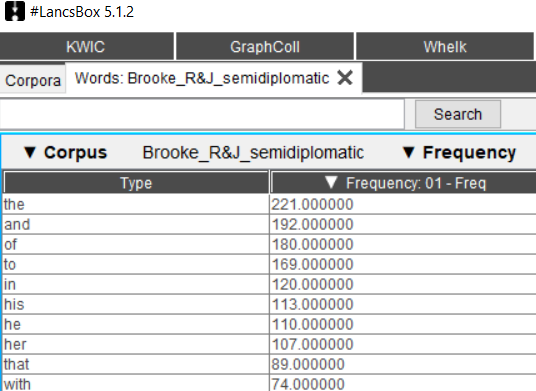
Any effective lexical analysis should start with keywords’ extraction. The Words tool (Fig. 5) allows examination of frequencies of types, lemmas and PoS, and comparison of subcorpora using the keywords technique.
Fig. 5. Top 10 most recurring words in the corpus selected.
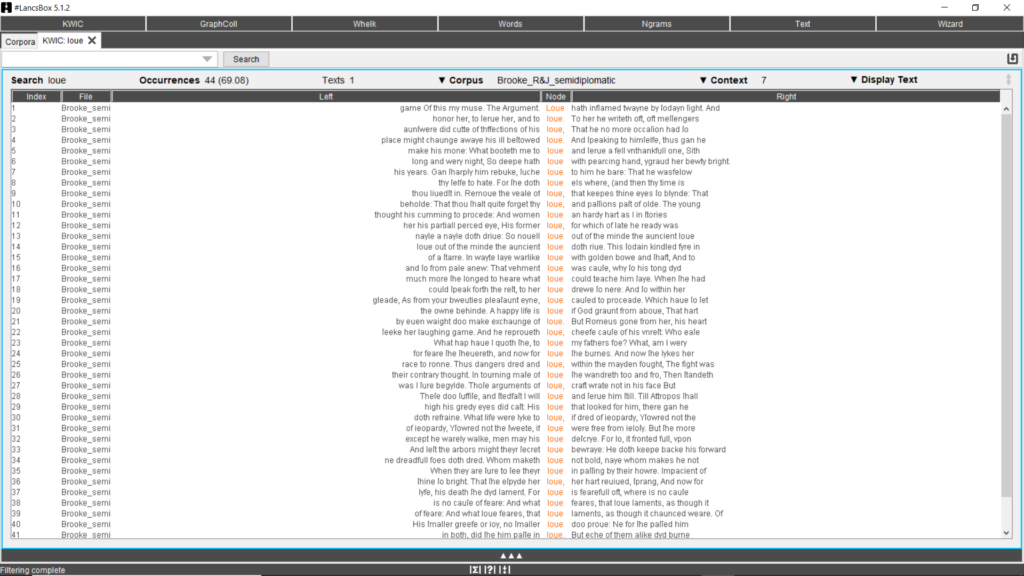
The KWIC (KeyWords In Context) tool generates a list of all left and right collocations of a search term (or node) in a corpus in the form of a concordance (Fig. 6). Occurrences of a search term are indicated right above the results, while the ‘File’ column indicates the text where the keywords appears.
Fig. 6. Left and right concordances of the node ‘loue’ searched by the KWIC tool.
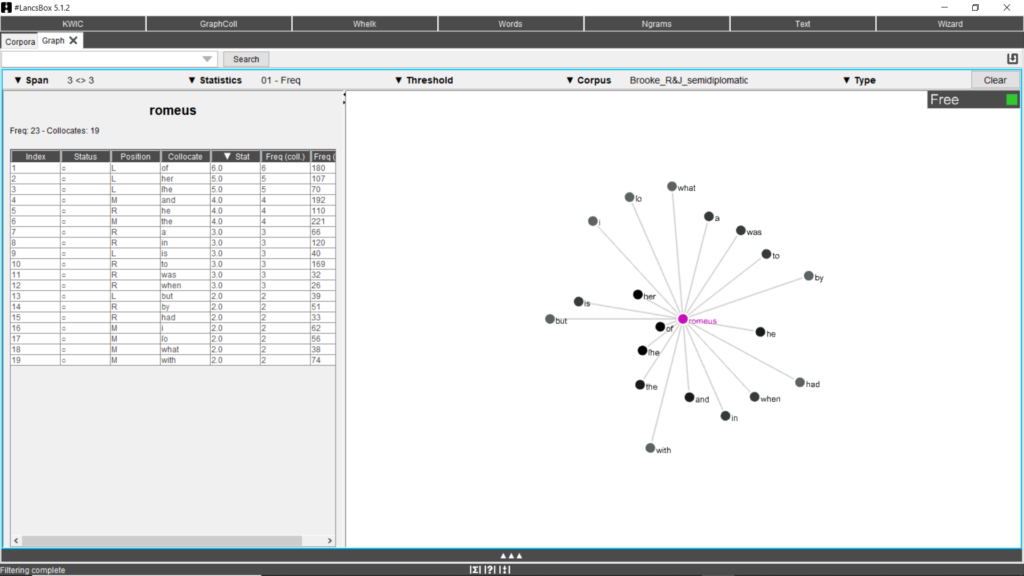
The results provided by the KWIC tool can be filtered and different parameters can be set by the GraphColl tool (Fig. 7). It identifies collocations and displays them in a table and as a collocation graph or network. A span of left/right collocations can be set (generally 3L-3R or 5L-5R) as well as a threshold level regarding the minimum number of occurrences per collocation (from 1.0). The left side of the screen shows the position of the collocates (L, R or M for middle, meaning sometimes on the left and sometimes on the right) and their frequency. The graphic collocational patterning is shown in the right part of the screen. Collocates are allotted according to their collocational position. The closer a collocate is to the node, the higher its frequency of occurrence with the search term.
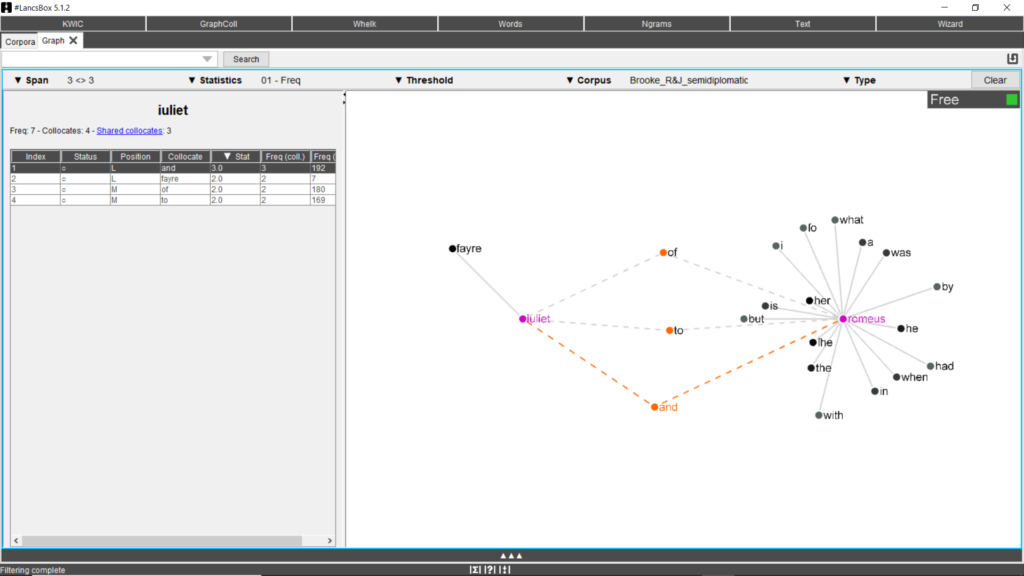
Fig. 7. Graphic collocations of the word “Romeus”.
Results can be cleared, but they can also be maintained and a new term searched, to compare the collocational patterning of more than one node (Fig. 8). The figure below shows the collocations that the search terms “Romeus” and “Iuliet” have in common (called shared collocates). For instance, such information is precious when research about semantic fields is carried out.
Fig. 8. “Romeus” and “Iuliet”’s shared collocates.
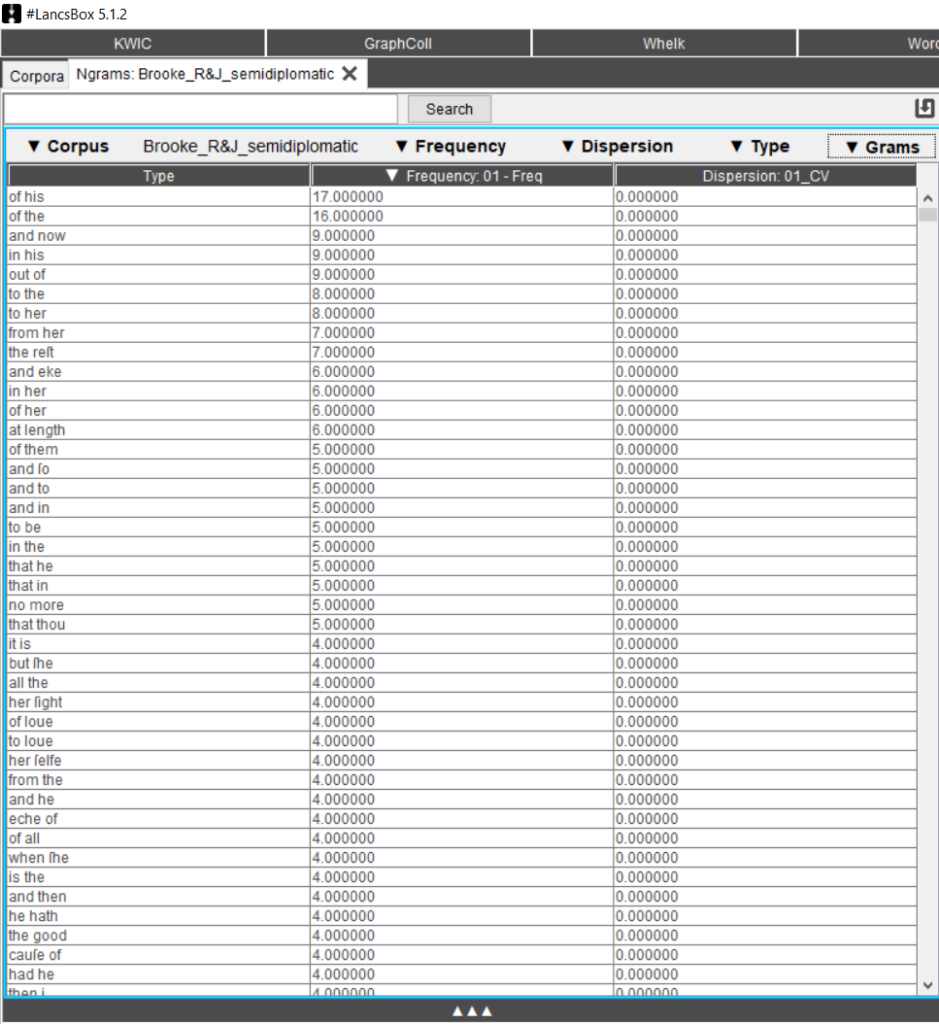
The Ngrams tool allows detailed analyses of frequencies of n-grams, thus focusing more on syntactic structures than morphology and lexis. By clicking on Ngrams, #Lancsbox provides results for 2-grams (the default search function. Fig. 9), but search settings can be adjusted up to 10-grams.
Fig. 9. 2-grams in the corpus selected.
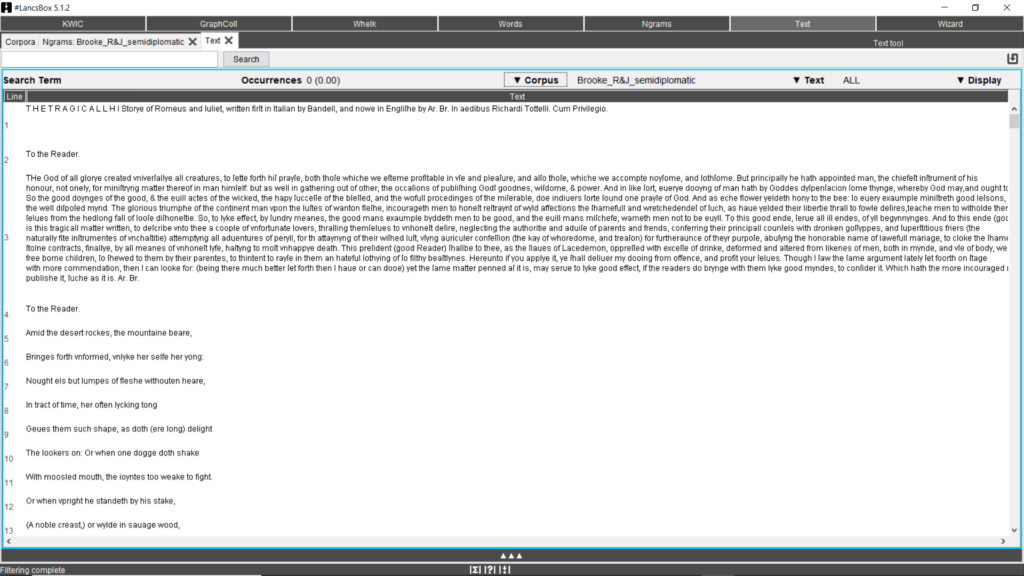
In any moment, it is possible to consult the whole corpus by clicking on the Text tool (Fig. 10).
Fig. 10. Plain text of Romeus and Iuliet as it appears by clicking on the Text button.
[1] Voyant tools (https://voyant-tools.org/) was developed by Stéfan Sinclair (McGill University, Montreal, Canada) and Geoffrey Rockwell (University of Alberta, Canada).
[2] #Lancsbox was developed by Vaclav Brezina and Tony McEnery at the University of Lancaster, UK (updated versions of this free software can be downloaded at http://corpora.lancs.ac.uk/lancsbox/)
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish. Cookie settingsACCEPT
Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Per ulteriori informazioni relative alle modalità di trattamento dei dati personali degli utenti che consultano i siti web dell'Università di Verona si rinvia alla seguente informativa: link
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.